[ad_1]
It seemed like a simple question: Can you figure out what’s in an ESD file without download the whole file? I’ve been manipulating data like this quite a bit over the past couple of days, so I’d like to think I’m getting pretty good at it — so I had to take that as a challenge.
First, Microsoft did publish a paper (available to download in RTF form here) that describes the file format. While you could probably reverse-engineer everything from just that, I found it useful to have a few other pieces of data to help:
- Source code from the open-source WIMLIB (useful if you ever want to create or use WIM/ESD files on other platforms, e.g. Linux or MacOS), available here. (You can read more about this in a previous blog post about making WIM images smaller.)
- A ProcMon trace showing a WIM/ESD file being opened by 7-Zip, which natively knows how to open WIM files to display their content.
- The same WIM/ESD file opened in the HxD so I could browse the whole file in hexadecimal. (I talked about that in another previous blog post about Autopilot hashes.)
The documentation discusses how each WIM file starts with a standard file header, where the first bytes are “MSWIM” as a “magic string” to verify that this is indeed a WIM file. And from the WIMLIB source code, I can see that the header is 208 bytes long. That’s nice, since that’s what ProcMon shows 7-Zip reading when I opened the file: the first 208 bytes of it.

After that, it read 7644 bytes from the near the end of the file, then a whole bunch of data that was just before that chunk. Logically, it seems reasonable to assume that it read the header, then the image information, then the actual file/directory structure that it needs to display.
First, we can verify the 208 (0xD0 in hex) byte header in HxD:

Sure enough, it starts with MSWIM. Let’s jump ahead in HxD to the location that ProcMon showed it reading, offset 3,740,696,980 or 0xDEF68194 in hex.

Nice, that’s a chunk of Unicode XML text. (I had forgot that WIM files used XML to store details about the images inside. If you remember the ImageX utility, it would dump that XML out for you, just as it is in the file.)
So then we just need to figure out where in the header (those first 208 bytes) we can find the offset and the length. From the WIMLIB source, I can see that the XML information is in a structure 0x48 bytes into the file. And in a separate source file, I can see that the offset is 8 bytes into that structure (so located at 0x50), with the following 8 bytes (located at 0x58) giving the total length.
Perfect, so we know what we need to do:
- Read the first 208 bytes from the file. We can do that using an HTTP request that asks for a byte range of the file, e.g. bytes 0-207.
- Make sure we have valid data by looking at the first five bytes to make sure they are “MSWIM” (don’t want to go off the rails if something went wrong reading the data).
- Extract the offset and length from the header and use that to make a send HTTP request that asks for that byte range.
- Convert the resulting string into an XML object so we can display it.
That’s all doable in PowerShell, right? Well, yes, but not as easily as I had hoped — you can’t use PowerShell’s provided cmdlets to make byte range requests, so we have to drop back to using .NET objects. So let’s walk through the process one chunk of code at a time.
First, we’ll make the script parameter driven, but for simplicity I hard-coded a default ESD file to try.
[CmdletBinding()]
param(
[Parameter(ValueFromPipelineByPropertyName = $True, Position = 0)][alias("URL")]
[String] $URI = "http://dl.delivery.mp.microsoft.com/filestreamingservice/files/ad6e5e87-14da-4577-a9da-dd345685efe8/22000.318.211104-1236.co_release_svc_refresh_CLIENTCHINA_RET_x64FRE_zh-cn.esd"
)
Next, we can make a request to read the 208-byte header:
# Read the header (208 bytes)
$request = [System.Net.WebRequest]::Create($URI)
$request.Method = "GET"
$request.AddRange("bytes", 0, 208)
$reader = New-Object System.IO.BinaryReader($request.GetResponse().GetResponseStream())
$bytes = New-Object Byte[](208)
$reader.Read($bytes, 0, 207) | Out-Null
As a sanity check, we can then check the header:
# Check the magic header
if ([System.Text.Encoding]::ASCII.GetString($bytes[0..4]) -ne "MSWIM") {
throw "Invalid WIM/ESD file, incorrect magic string in header"
}
Next, we can get the offset and length from the header:
# Get the offset and length
$offset = [System.BitConverter]::ToInt64($bytes, 80)
$length = [System.BitConverter]::ToInt64($bytes, 88)
And that enables us to get the Unicode XML string, which PowerShell can convert to an XML object:
# Read the XML from that location
$request = [System.Net.WebRequest]::Create($URI)
$request.Method = "GET"
$request.AddRange("bytes", $offset, $offset + $length - 1)
$reader = New-Object System.IO.StreamReader($request.GetResponse().GetResponseStream())
[xml]$xml = $reader.ReadToEnd()
And finally, the script can return the list of images, massaged into something that is a little easier to consume than the XML object:
$xml.WIM.IMAGE | % {
New-Object -TypeName PSObject -Property @{
INDEX = $_.INDEX
NAME = $_.NAME
DESCRIPTION = $_.DESCRIPTION
FLAGS = $_.FLAGS
EDITION = $_.WINDOWS.EDITIONID
LANGUAGE = $_.WINDOWS.LANGUAGES.LANGUAGE
VERSION = "$($_.WINDOWS.VERSION.MAJOR).$($_.WINDOWS.VERSION.MINOR).$($_.WINDOWS.VERSION.BUILD).$($_.WINDOWS.VERSION.SPBUILD)"
}
}
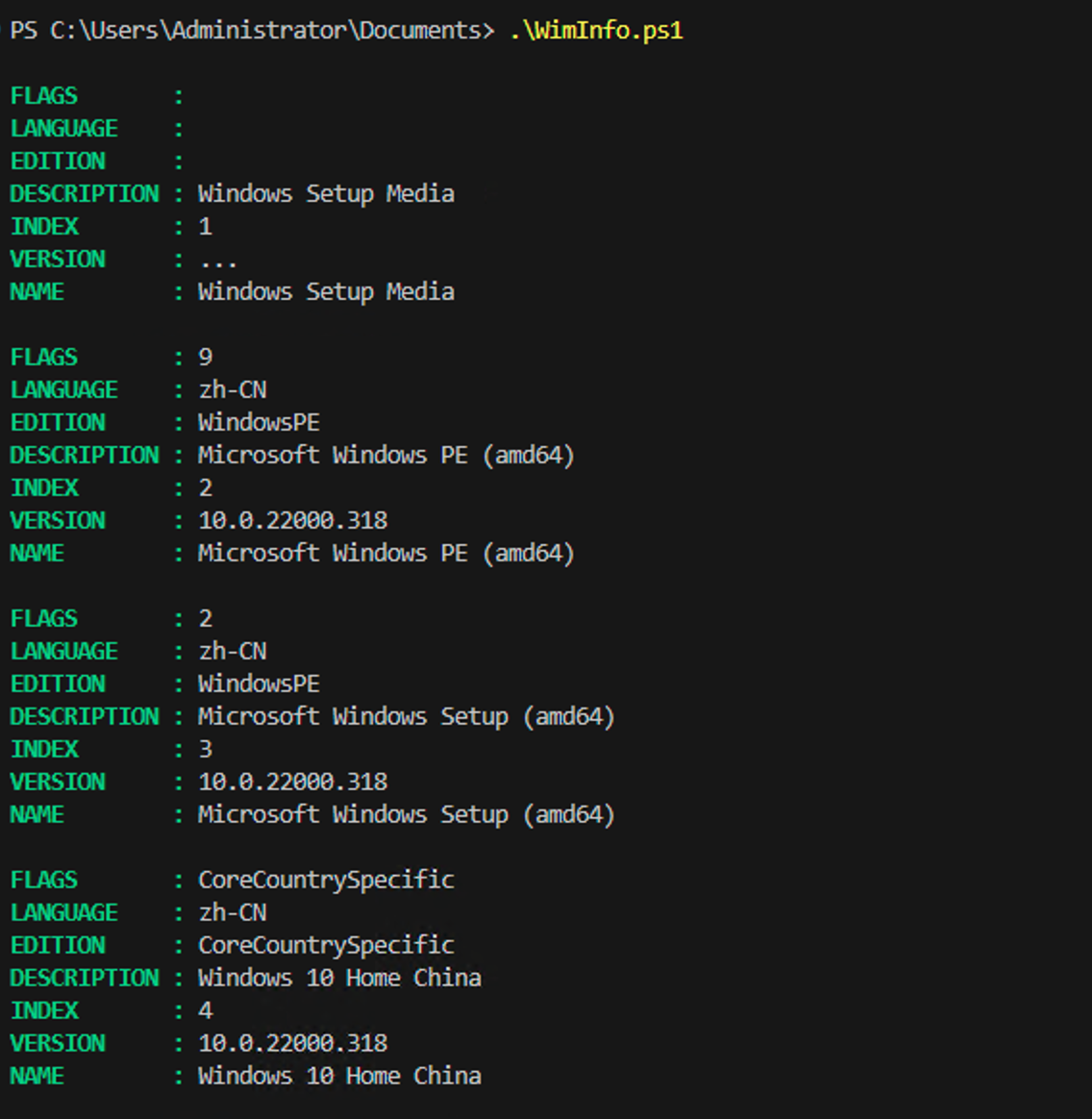
And here’s what we see as a result:

Very nice, for about 10KB of network traffic. But before we wrap this up, there was one other oddity that I noticed: There was stuff in the ESD file after the XML data. If you look at a “normal” WIM file, the XML is at the end, which makes sense: the capturing process writes all the new file/directory data (overwriting the old XML since it will be replaced anyway), then writes new XML data to the end of the file. That assumes that the XML is at the end of the file, which for this ESD file is not the case. So what is after it? Scanning through it in HxD, you get some hints:

The ESD files have been Autheticode-signed. So if you downloaded the whole file, you could validate those Authenticode signatures to determine if the file has been tampered with. And obviously appending a new image to the file would be “tampering” so it’s quite OK to overwrite that stuff when modifying the ESD/WIM file; you’re going to have to re-sign it anyway. (It’s a fairly common technique that you’ll see used with a bunch of different file formats: drop signing or checksum information at the end of the file. Tools, e.g. 7-Zip, that read the files will generally ignore that data, so it’s fairly harmless.)
If you are curious about what the first three images are in the ESD files, those are what you would need to create full bootable media: the first image has the setup files, the second is a generic Windows PE boot image (index 1 in your standard boot.wim), and the third is the Windows PE boot image with Setup integrated into it. So you can construct the media from those three. (See this module to see how. Notice that I ignore the second image because boot.wim index 1 is not really needed when installing from media.)
So back to the original question: Can you figure out what’s in an ESD file by just reading a small chunk of the overall file? Yes, most definitely.
The complete script is attached.
Attachment: WimInfo.zip
[ad_2]
Source link



